サスティナブル・アーカイブ・ギャラリーあまのがわは、NPO法人地域資料デジタル化研究会がたどりついた持続可能なデジタルアーカイブのカタチです。大きく分けで2つの考え方でできています。
- デジタルアーカイブの本体はマスターとなるメディアファイルと目録情報によって構成されており、ウェブは共有のための手段として捉える。
- 共有のためのウェブは、原則的にすべて静的HTMLファイルにより構成され、HTML、CSSを基本とし、ローカルで稼働する範囲内でJavaScriptを用いる。
というように、マスターデータの管理とどんなウェブサーバにもフォルダをコピーすれば移行可能(インターネットに接続していないローカルのHDDやUSBメモリなどのストレージ上でも閲覧できる)をポイントとしています。
資料全体の分量を把握し、デジタルアーカイブ全体のデザインを行うとともに、作業工程管理を含めた資料一覧、保存袋一覧を作成します。
お問い合わせ
まずはお問い合わせください。
会社の創業時からの写真があるのだけど、どうしたらよいかわからない。家の蔵を取り壊すのだけど、中に古いものがたくさんある。地域の公民館には地域の古い写真や歴代の区長さんの写真があるのだけど…
などなど。地域の歴史や文化、先人の方々の汗と涙の歴史があります。私たちはそうした歴史を地域の記憶として共有するために、デジタル技術を用いたアーカイブを構築しております。
資料計量(概算)/お見積もり
お問い合わせいただいたのちに、実際の資料を拝見させていただきます。
おおよその分量から計量し、概算のお見積りとおよそのスケジュール(納期を含む)を作成いたします。もちろん、お見積りは無料です。
お申し込み
お見積り金額とスケジュールをご確認いただきましたら、お申し込みのご判断をいただければと存じます。
また、ご予算に応じて、分割によるデジタルアーカイブも可能ですので、ぜひご相談ください。
資料受取り
お申し込み、ご発注いただきましたら、私どもで資料の受け取りにお伺いいたします。
資料計量(詳細)
資料をお預かりしたのちに、デジタル化する点数などを詳細に計量し、詳細のお見積もりを再度作成いたします。
仕分け/保存袋分け
デジタル化の工程に入るまえに、資料の仕分け保存袋に入れる作業を行います。この時点で、デジタルアーカイブの共有のためのウェブページの作成点数がおおよそ確定いたします。
作業書作成
仕分け/保存袋分けと同時進行で、
- デジタル化する資料へのID(ファイル名の元になります)
- 保存袋(セット)に対するID(フォルダ名となります)
- デジタル化作業、目録作業、Webページ作成作業などの工程表を作成します。
スケジュール表
資料一覧作成-資料id
資料一点一点に、ID番号を付与します。これはメディアデータのファイル名(拡張子は資料の種類による)のベースとなります。
一例ですが、[資料識別文字]-[保存袋ID]-[資料ID].(拡張子) となります。
保存袋一覧作成-保存袋id
保存袋に、ID番号を付与します。これは各メディアデータを保存するフォルダ名のベースとなります。
一例ですが、[資料識別文字]- set[保存袋ID] のようになります。
デジタル化作業-スタジオ作業
現物資料
現物資料の状態を確認しながら、折れやシワを伸ばしながら、できるかぎり現物資料を良い状態でデジタル化作業に取り組みます。またこのとき資料の状態など気になる箇所は、目録情報の「備考欄」に記入しておくと良いでしょう。
デジタル化機材
デジタル化機材は、次のとおり
- 紙資料(A3サイズまで):フラットベットイメージスキャナをメインにデジタル化作業を行います。
- 紙資料(A3サイズ以上):A3サイズのフラットベットスキャナでは入りきらないサイズは、写真撮影によるデジタル化作業になります。
- アルバム写真(台紙から剥がせる):一点一点紙焼きされている写真は、フラットベッドスキャナかドキュメントスキャナを使います。
- アルバム写真(台紙から剥がせない):台紙から剥がせない写真は、そのままアルバムのページをフラッドベッドスキャナでデジタル化し、後の作業において個々の写真を切り出します。
- フィルム:写真用の35mmフィルムは、フィルムスキャナにてデジタル化します。
- ファイル:ムービー用8mmフィルムは、ムービー用のデジタル化機器にてデジタル化します。
- 音声:音声再生装置を用いて再生し、オーディオインターフェイスを介してパソコン側の録音ソフト等を用いてデジタル化します。
- 映像:ビデオなどは再生装置を準備して、映像信号をビデオキャプチャ機器を介してパソコン側の録画ソフト等を用いてデジタル化します。
パソコン
パソコンは、WindowsOS、macOSなどの機種で作業をすることができます。ChromeBook等はスキャナドライバーなど対応が十分ではないので、デジタル化作業には向いていません。また、スマホやタブレットなども写真撮影機能として用いることはできますが、書面状のものはフラットベッドイメージスキャナを用いるとよいです。
デジタル化ソフト
イメージスキャナ付属のスキャナドライバーをインストールしたのちに、スキャニングソフトや画像編集ソフトからスキャン機能を呼び出して画像取り込みをするとよいです。
スキャニング作業は、プリンタスキャナ複合機でも可能です。その場合は複合機のドライバーをインストールしてご利用ください。
作業者
デジタル化に限らず、デジタルアーカイブ構築に関わったすべての人を奥付け情報/クレジット情報として記載するスタイルも、サスティナブル・アーカイブ・ギャラリーあまのがわ のスタイルです。
画像処理作業-画像処理ソフト
画像補正
傾き補正
トリミング
ノイズ除去
画像合成
メタデータ付与-Adobe Bridge
Adobe Bridge を用いて、画像ファイルの中にIPTCやExifなどの形式で情報を書き込みます。
IPTC
Exif
マスターメディアファイル
以上のように、デジタル化作業には
- デジタル化(現物資料がないとデジタル化はできない)
- ポスト作業:画像補正、傾き修正、トリミング、ノイズ除去など
- 画像ファイルへのメタデータ付与
- デジタル化の検品を受けて、次の工程に入ります。
事前作業で作成
目録作成作業は、現物の資料をみながら判断し、情報を確定することがたくさんあります。基本的には、各資料一覧表に目録項目を埋めていく作業となります。
- 資料一覧/ 資料ID
- 保存袋一覧/保存袋ID
もともと、書籍や映像作品のようなタイトルがついていない写真や文書などがほとんどなので、その資料の名称確定から作業が始まります。
資料からの情報
基本的に「地域資料デジタル化研究会目録規則」を作成しています。目録規則には、どのような形態の資料であってもすべての資料に共通で付与する「目録コア」と、資料ごとに付与する「メディア項目」およびさらに詳細の「目録アドバンス」の段階があります。
まずは、目録コアを付与することで資料の検索が可能になります。
- 目録コア(暫定版)
- 名称
- 名称ふりがな
- いつ
- どこで
- 誰が
- どのような資料か
- どのくらいの大きさ/重さか
- 備考
※ 地域資料デジタル化研究会における地域資料のデジタルアーカイブのための目録規則を準備中
組織化に必要な情報
リチャード・ワーマン氏によるLATCHを基本に、情報を組織化して、目次・索引ページとして作成します。情報の組織化は、既存の知識と照らし合わせて、おおよそ探し求めている情報がどのあたりにあるのかの目星をつけることができ、探し出すための時間を最小限にすることが目的です。リチャード・ワーマンはまだインターネットが登場する以前、Googleでの検索が登場する前から、情報が溢れる時代における情報の組織化に取り組んでいいました。その彼がたどりついた情報組織化の5つの方法が LATCH (ラッチ)です。
サスティナブル・アーカイブ・ギャラリーあまのがわにおいては、生成型静的HTMLにより全資料をHTMLファイルで作成します。ウェブシステムとしてのデータベースを用いない分、情報の組織化によって情報を探すことができるようにしています。
【参考資料】『情報選択の時代』『それは「情報」ではない』
Location: 場所
地図や地名、場所による情報の組織化です。あまのがわスタイルでは、資料が生成あるいは資料に関係の深い[地名]をもとに、国が定めて都道府県コードならびに市町村コードによって並べています。これにより北海道から沖縄までの資料を地域で探すことができるようになります。
Alphabet: アルファベット/50音順
リチャード・ワーマンは、英語圏なのでAlphabet(アルファベット)を用いていますが、日本において50音順(あいうえお順)によって資料を組織化しています。基本的には資料ではなく、保存袋を対象として、その名称にふりがなを付与。保存袋のふりがなをもって50音順に並べて、資料を探しやすくしています。
Time: 時間
資料が生成された時代/年月日を基本として情報を組織化します。保存袋には含まれている資料の代表的な制作年を西暦で付与していますので、西暦と和暦を併記したかたちで、年代順に並べることで 時間軸での資料の探しやすさを高めています。
Category: カテゴリー(種類)
資料の形態や種類によって組織化することも、資料の探しやすさにつながります。資料の種類、資料の形態などは、今後カテゴリーとして充実させていきます。
Hierarky: ヒエラルキー(階層)
ヒエラルキーという言葉を用いると少し理解が難しいかもしれませんが、大きさや数字の大小を降順/昇順で並べることを指していると考えてください。資料のサイズは最終的には収蔵する棚の大きなさどにも関係しています。
ここで、リチャード・ワーマンの上記 LATCH に加えて、今後の情報の組織化手法として次の2点を考えています。
Story / Narrative(物語)
実はまだ文字が発明される前から、人類は口述によって情報を組織化していました。それが物語です。時代や人物、場所や組織などが物語によって関連づけられており、脳以外の記録手法を持たない頃から「記憶」として情報を組織化する手法が「物語」であると捉えています。ここのデジタルアーカイブから物語を紡ぎ出すのはまだ少し時間がかかりますが、デジタルアーカイブの資料組織化の手法として「物語化」があることをおさえておきたいと考えます。
Playlist(リスト)
音楽サービスなどで、好きな音楽をプレイリスト化すること。これもまた情報の組織化の手法であると考えています。上記のLATCHや物語化だけでなく、「好きな情報を集めてみました」もまた資料組織の方法であると捉えています。国立国会図書館のジャパンサーチにおいても、登録利用者がさまざまなアーカイブから自分だけのギャラリーをつくる機能を提供しています。従来のデジタルアーカイブのまとまりを超えて、なんらかのテーマは嗜好によってつくる「プレイリスト」のかたちもまた、情報組織化の手法であると考えています。
保管と二次利用のために必要な情報
所有者
二次利用の許諾を得るためにも、資料の所有者を明確にし、二次利用の許諾等の手続きを容易にするための情報を記載します。
保管場所
現物資料の保存施設を記載します。ウェブで共有したアーカイブ資料の現物を見るための情報となります。
二次利用条件
基本的に、画像等のサムネイルサイズと目録情報は、資料所有者の同意のうえで、PD(パブリックドメイン)またはCC0、CCbyなどのできるだけ許諾等の手続きをとらずに利用できる条件にしたいと考えております。
ただし、オリジナルのメディアデータや現物の資料そのものを使いたい場合などは、必要な手続きによる許諾を必要とする場合もあるかと思っております。
目録作成時の注意事項
目録作成においては、[地域資料デジタル化研究会目録規則]に準じた作成を行いますが、パソコンでの作業の大原則として同じ情報を二度は入力しないことを徹底させたいと考えています。これは作業効率だけではなくコピーペーストの間違いや誤入力の元凶になります。マスター(台帳)をつくりlookup機能あるいはリレーション機能を用いながら目録データを作成することが大事だと考えています。
スタティックなHTML
サスティナブル・アーカイブ・ギャラリーひまわり において、地域資料デジタル化研究会が取り組むデジタルアーカイブは、特定のWeb+DBシステムに依存せず、特定のデジタルアーカイブシステムに依存せず、移転も可能なレガシーなウェブのスタイルをとっています。
- 静的なHTMLファイル(スタティックなHTML)
- CSS
- JavaScript
- サムネイル画像
現在のスタート時点においては、静的HTMLファイルとCSSの組み合わせで作成しています。
- テキストエディタ(Visual Studio Codeなど)を用いて、基本となるHTMLファイルを作成します。
- 基本となるHTMLファイルの中で、デジタルアーカイブとしての資料毎に変化する場所を決めます。
- <html><head></head><body></body></html>の大きなくくりを把握
- <head></head>の記述で、すべてのファイルで同じ部分と、個々のファイルで違う部分とに分けます。
- <body></body>の記述の中では、<header></header><mail></main><footer></footer>を意識しながら、すべてのファイルで同じ記述と、個々のファイルで異なる記述の場所を把握します。
こうして、すべてのファイルで共通部分と、個々の資料で目録情報を元にして異なる記述部分とを把握して、次の自動生成型静的HTMLのためのプログラミングづくりに取り組みます。
プログラミングによる生成型静的HTML
資料一覧、保存袋一覧の目録データを、基本となるHTMLファイルに差し込みながらHTMLをひとつひとつ書き出す方法で、数件〜数千件の各資料アイテムのページを生成するプログラムを作成します。
- FileMaker Pro
- MS-Excel + VBA
- Googleスプレッドシート + GAS
- Python
現在のところ、FileMaker Proを用いた自動生成型静的ウェブを構築しています。すべてのファイルに共通する部分はテキストフィールドとしてグルーバル変数(すべてのレコードで共通)として入力、目録情報のExcelファイルを読み込み、関数フィールドを作成して、共通部分と個別部分の文字列を繋ぎ合わせて新しいフィールドを作成します。
最終的には、個々の静的HTMLファイルになる計算フィールドにまとめ、資料一覧IDや保存袋IDなどから生成するファイル名を用いて、自動的にHTMLファイルを書き出させます。
一度、このプログラムができてしまうと、数百件、数千件の自動生成型静的ウェブページの作成は、数秒で書き出すことが可能になります。
組織化ページ(目次・索引としてのHTMLページ)
組織化ページ(保存袋一覧、地名順、時間順など)は、上記の静的ウェブの中でも<main></main>のパートの中に、自動で書き出したリストタグのHTMLコードを、テキストエディタを用いて組み込むことで作成できます。
- すべての保存袋
- 場所順
- 時間順
- 50音順
は、それそれ1つのHTMLファイルなので、あえて自動化する必要はないのですが、最終的なバージョンではこのあたりも自動生成でファイルを書き出せるようにすることも検討しています。
マスターメディアデータからのサムネイル(JPEG)の生成
生成型静的ウェブのページに用いるサムネイル画像は、次のように作成します。
- マスターとなるメディアデータ(画像)を確定(TIFF形式)
- デジタルカメラのRAW形式での撮影は同時にJPEG形式での保存も可能であるので、それを用いで同じ解像度のJPEGファイルを作成
- Adobe Photoshopのイメージプロセッシング…機能を用いて、特定のフォルダ(サブフォルダを含むを指定すると作業が早い)の画像を、指定したフォルダに、指定した解像度で変換し新規で保存することができます。
- オリジナルサイズのJPEGファイルを出力
- Lサイズ(長辺1280px)、Mサイズ(長辺640px)、Sサイズ(長辺320px)を、それぞれLサイズのフォルダ、Mサイズのフォルダ、Sサイズのフォルダに変換保存します。
- この時のサムネイルを保存したファイルへのパスは、上記の自動生成プログラムでサムネイル画像の埋め込みを指示するために用います。
基本的なツリー構造
public_htmlフォルダ内に作成は、関本家資料の場合は次のようになります(途中省略)
├── JPEG
│ ├── L
│ │ ├── digiken_skmtd_0001.jpg
│ │ │ (Lサイズ画像)
│ │ └── digiken_skmtp_0248.jpg
│ ├── M
│ │ ├── digiken_skmtd_0001.jpg
│ │ │ (Mサイズ画像)
│ │ └── digiken_skmtp_0248.jpg
│ ├── O
│ │ ├── digiken_skmtd_0001.jpg
│ │ │ (オリジナルサイズ画像)
│ │ └── digiken_skmtp_0248.jpg
│ └── S
│ ├── digiken_skmtd_0001.jpg
│ │ (sサイズ画像)
│ └── digiken_skmtp_0248.jpg
├── artmuseum.html (山梨県立美術館への寄贈資料一覧)
├── digiken_skmtd_0001.html
│ (各資料の静的HTML)
├── digiken_skmtp_0248.html
├── images
│ ├── apple-touch-icon.png
│ ├── digi-ken_logo-300x94.png
│ ├── digiken_skmtd_1819.jpg
│ └── favicon.png
├── index.html (トップページ)
├── kaijium.html (山梨県立博物館への寄贈資料一覧)
├── literarymuseum.html (山梨県立文学館への寄贈資料一覧)
├── set_skmt_001.html
│ (保存袋の静的HTML)
├── set_skmt_272.html
├── skmt_aiueo.html (50音順一覧)
├── skmt_location.html (場所順一覧)
├── skmt_outline.html (デジタルアーカイブ概要)
├── skmt_set_all.html (保存袋一覧)
├── skmt_timeline.html (年代順一覧)
├── skmt_use.html (利用にあたって)
└── style.css (スタイルシート)
主なソフトウェア
HTML生成: FileMaker Pro, MS-Excel, Googleスプレッドシート, Pythonなど
Microsoft Excel スプレッドシート ソフトウェア | Microsoft 365
Microsoft Excel は業界をリードするスプレッドシート ソフトウェア プログラムであり、強力なデータ可視化と分析のツールです。Excel で分析をレベルアップしましょう。

テキスト編集:Visual Studio Code
Visual Studio Code – コード エディター | Microsoft Azure
ほぼすべての言語で動作し、任意の OS で実行される強力なコード エディターである Visual Studio Code を使用して、Azure 上で編集、デバッグ、デプロイを行います。
サムネイル作成: Adobe Photoshop のイメージプロセッサ機能

メディアデータへのメタデータ書き込み: Adobe Bridge
※ 追記
Microsoft Wordの差し込み印刷機能を使ったことはありますか?
ワードで作成したテンプレート文章の中に、エクセルシートで作成した一覧表の各行からのデータを逐次埋め込みながら、1つのテンプレートで変数部分の異なる複数の印刷ができる機能です。
生成型静的HTMLの出力は、基本的に差し込み印刷するように、ひとつひとつのHTMLファイルを書き出すようなものだと思ってください。
実際には、ワード+エクセルによる差し込み印刷や、Googleドキュメント+Googleスプレッドシートによる差し込み印刷機能でHTMLファイルを作成することはできませんが、一覧表になったデータをテンプレートの {{変数部分}} に代入しながら一件一件のファイルを書き出すようなものとなります。
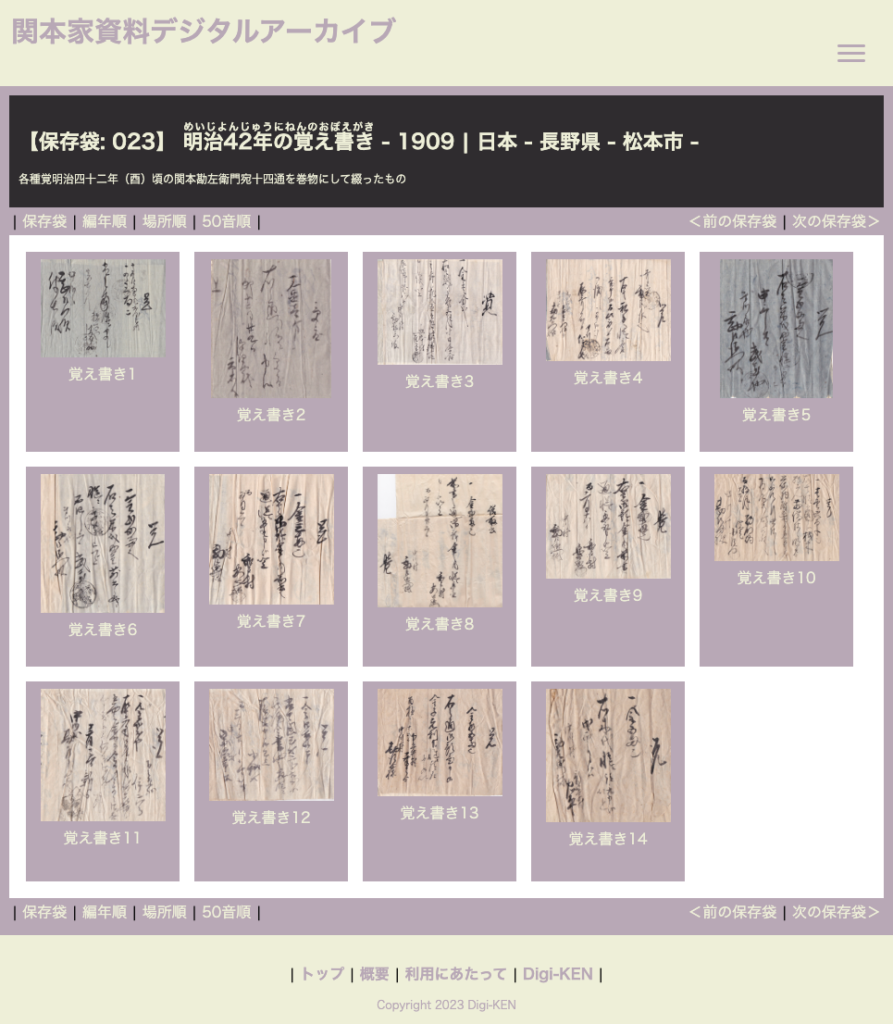
関本家資料デジタルアーカイブの場合
関本家資料デジタルアーカイブでは、次のようなページを作成しました。







トップページ
トップページにおいては、基本的なページデザインも含めて、テキストエディタ(Visual Studio Code)にて作成しています。
このページをつくりながら、関本家資料デジタルアーカイブのページ全体にかかわるデザインをHTMLで作成します。
デザイン上のページ全体の構成、ヘッダーとなる部分、メニューの配置、ボディーとして表示する部分、ページの下部、フッターとなる部分などのパーツを意識しながら、ページを作成しています。
また、特定のサーバにアップロードすることで、関本家資料アーカイブのURLが確定するので、Googleサイト内検索のコードを作成し、こちらも手入力にて組み込んでいます。
資料保存袋 (リスト部自動生成後、テンプレートに手動組み込み)
資料保存袋、編年順一覧、場所順一覧においては、基本的なページ構成からヘッダー部分、メイン部分、フッター部分とわけて、メイン部分となるリストのみを自動生成し、テンプレートとなるHTMLのメイン部分に組み込んでいます。
保存袋一覧のリスト部分は、
<li>(自動書き出し)</li>
にて作成しています。
編年順一覧 (リスト部自動生成後、テンプレートに手動組み込み)
資料保存袋、編年順一覧、場所順一覧においては、基本的なページ構成からヘッダー部分、メイン部分、フッター部分とわけて、メイン部分となるリストのみを自動生成し、テンプレートとなるHTMLのメイン部分に組み込んでいます。
保存袋一覧のリスト部分は、テーブルタグの要素として
<tr><td>(自動書き出し)</td></tr>
にて作成しています。
場所順一覧 (リスト部自動生成後、テンプレートに手動組み込み)
資料保存袋、編年順一覧、場所順一覧においては、基本的なページ構成からヘッダー部分、メイン部分、フッター部分とわけて、メイン部分となるリストのみを自動生成し、テンプレートとなるHTMLのメイン部分に組み込んでいます。
保存袋一覧のリスト部分は、テーブルタグの要素として
<tr><td>(自動書き出し)</td></tr>
にて作成しています。
50順一覧 (リスト部自動生成後、テンプレートに手動組み込み)
トップページにおいては、基本的なページデザインも含めて、テキストエディタ(Visual Studio Code)にて作成しています。
保存袋一覧のリスト部分は、テーブルタグの要素として
<li>(自動書き出し)</li>
にて作成し、見出しとしてあ行、か行〜わ・を・ん をあらかじめテンプレートのメイン部分に作成し、書き出したリストのテキストファイルから、手動でカット&ペーストして作成しています。
保存袋ページ (全ページ自動生成)
保存袋ページにおいては、CSSによるFlexbox(フレックスボックス)を基本にサムネイル表示のページを作成しています。
このページの表現においては、Flexboxの記述によって大きく変化します。
Flexbox内の記述をどのように自動化させ、保存袋ページの全ページをいかに自動化してHTMLファイルとして書き出すかがポイントとなります。関本家資料においては、211個の静的HTMLファイルを自動生成しています。
資料詳細ページ (全ページ自動生成)
資料詳細ページにおいては、基本となるテンプレートを作成し、サムネイル表示部分と目録情報となるテーブル部分を作成してHTML記述を作成。資料番号に基づきそれぞれのレコードをファイル名フィールドの名前で自動生成しています。
関本家資料デジタルアーカイブにおいては、1717件の静的HTMLファイルを自動生成しています。
style.css - スタイルシートについて
関本家資料デジタルアーカイブを第一弾とする サスティナブル・アーカイブ・ギャラリーあまのがわ では、上記のようなスタイルでのデジタルアーカイブ構築に取り組んでいきます。その際、HTMLの自動生成だけでなく、Flexboxなどを含めてスタイルシートの存在はとてもおおきなものです。HTMLファイルを変更せずに全体のデザインを変更することも可能です。
今回は、スタイルシートの中において変数を用いた 配色パートを作成しています。基本的に3色の配色+白・黒の5色によってこのスタイルを作っています。
以下の参考図書から、3色の配列による色指定部分を変数とし、スタイルシートの中の色指定部分を変数にすることで、3色のみを入れ替えるだけで、カラーバリエーションをつくることができます。
/* カスタムプロパティの設定*/
:root{
--base-color: #40220f; /* ベースとなる色 ページの地の色*/
--accent-color: #c9bc9c; /* 表題表示エリア、FlexBoxアイテムの色 */
--sub-color: #a19587; /* メインエリアの色 */
}参考図書をもとに、FileMaker Proで作成した配色用のデータベース
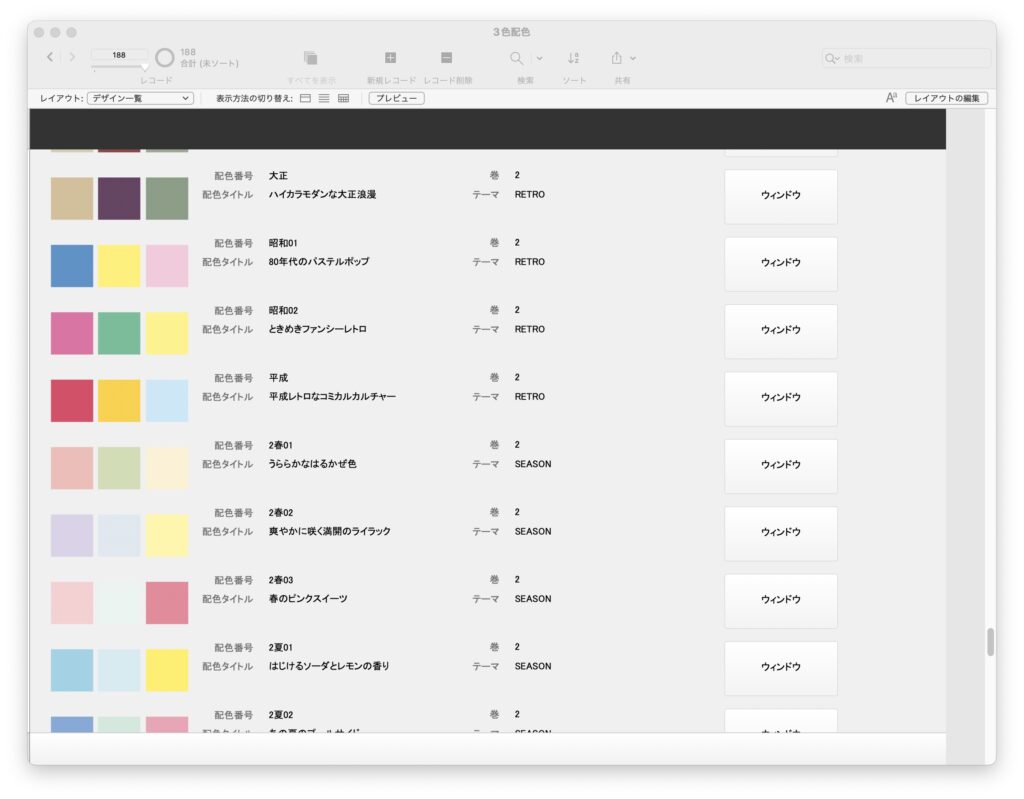
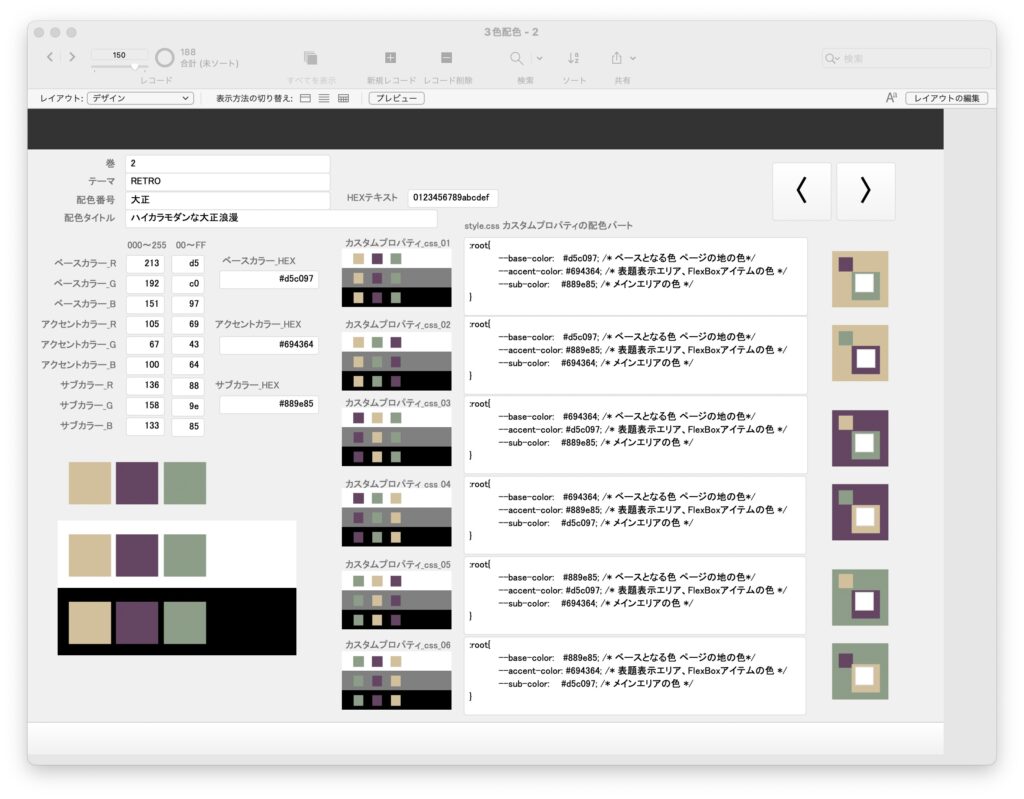
配色バリエーション
--base-color: #889e85;
--accent-color: #d5c097;
--sub-color: #694364;

--base-color: #eeefd8;
--accent-color: #2f2c2f;
--sub-color: #b8a8b6;
--base-color: #ef8bb6;
--accent-color: #ffda2a;
--sub-color: #31b6a0;

【参考図書】
- 『見てわかる、迷わず決まる配色アイデア 3色だけでセンスのいい色』 ingectar-e (著)/インプレス
- 『見てわかる、迷わず決まる配色アイデア 3色だけでセンスのいい色PART2』 ingectar-e (著)/インプレス
マスターメディアファイル
- オリジナルデータ(TIFF、RAWなど)を、保存袋単位でフォルダ/ディレクトリに保存したもの
- オリジナルデータと同じ解像度のJPEGを、すべてひとつのフォルダ/ディレクトリに保存したもの
目録データ
- Excelデータ(資料一覧、保存袋一覧はそれぞれのシートに分ける)
- Excelデータの各シートごとに、csv(カンマ区切りテキストファイル)で保存
公開用ウェブ
public_htmlフォルダに生成型静的ウェブスタイルで保存
- HTMLファイル
- CSS
- JavsScript
はじめにお読みください.txt
- readme.txt / はじめにお読みください。
- 記述フォーマットの標準化とXML記述
- めざすは、デジタルアーカイブ記述言語(DAML: Digital Archive Markup Language)
マスターUSBメモリの構成
関本家資料デジタルアーカイブのお引き渡しをしたUSBメモリのファイル構成です。

マスターUSBメモリは箱づめして納品します。

公開用あまのがわサーバ
公開用のHTMLを保存するフォルダ/ディレクトリ
公開用のサーバのpublic_htmlフォルダ内に、デジタルアーカイブ用のフォルダを作成します。
サブFTPアカウントの作成
デジタルアーカイブに関するすべてのファイルをアップロードするために、FTPアカウントを作成します。
Googleの各種設定
GoogleID(Gmail)を取得
Googleの各種サービスを利用するために、GoogleIDの取得が必要です。
基本的には、ひとつのデジタルアーカイブに対して、ひとつのGoogleIDを取得しておくことをおすすめします。
Googleサイト内検索
デジタルアーカイブを特定のドメイン名のサーバにアップロードすることで、URL(ユーアールエル)が確定します。そのURLをもってGoogleサイト内検索用のコードを作成します。
上記のページで作成した検索エンジンのコードを取得し、必要なHTMLファイルに組み込みます。検索窓や検索結果の表示などさまざまなデザインが選択できるので、サイトに適したデザインを作るとよいです。
ただし、Googleサイト内検索には広告が表示されますので、気になる方は御周囲ください。
<script async src="https://cse.google.com/cse.js?cx=■■■■■■■■■■■■■■■■■">
</script>
<div class="gcse-search"></div>Google Search Console用のサイトマップファイル(sitemap.xml)
Google Search Consoleは、作成したデジタルアーカイブのすべてのページがGoogleによって検索対象となるために、手動にて登録するページです。
Google Search ConsoleのURL検査にトップページとなるURLを入力するとともに、サイトマップの登録も忘れずに行います。
- URL検査 https://amanogawaginga.jp/sekimotoke/
- サイトマップ https://amanogawaginga.jp/sekimotoke/sitemap.xml
サイトマップファイルは、手動で作成することも、生成型生的ウェブで作成することも可能ですが、既存のサイトマップ作成サイトを利用すると、最初の URLを入力するだけで自動的に作成してくれますので、そうしたサイトを利用するのもひとつの方法です。
Google Analytics 4 用のタグコードを作成
デジタルアーカイブへのアクセス統計を測定するためには、すべてのページにGoogle Analytics 4 のタグコードを埋め込む必要があります。
- Google Analytics アカウントの作成
- プロパティの作成
- プロパティ名
- レポートのタイムゾーン 日本 (GMT+09:00) 日本時間
- 通過 日本円(¥)
- [次へ]
- ビジネスの説明
- 業種(必須) 仕事、教育 を選択
- ビジネスの規模(必須) ◉ 小規模 - 従業員数 1〜10名
- [次へ]
- ビジネス目標を選択する
- 見込み顧客の発掘
- オンライン販売の促進
- ブランド認知度の向上
- ユーザー行動の調査
- [作成]
- データ収集を開始する
- ウェブを選択
- ウェブサイトのURL
- ストリーム名(ウェブサイト名)
- [ストリームを作成]
- 実装手順を参考にコードを取得
- プロパティ名
<!-- Google tag (gtag.js) -->
<script async src="https://www.googletagmanager.com/gtag/js?id=G-P90FGF1VW7"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'G-P90FGF1VW7');
</script>GA4のタグコードを全ページに埋め込む
上記の Googleタグを、スタティックHTMLのすべてのページに組み込みます。方法としては、生成型成的ウェブの仕組みに組み込んで、すべてのHTMLページを生成させるか、Visual Studio Codeなどのテキストエディタで、フォルダ内のすべてのファイルに対する検索置換機能を用いて組み込みます。
robot.txt
ウェブ上にHTMLをアップロードした際に、すぐにGoogleのクロールを禁止させるために、robot.txt を配置しますが、公開後各種Googleの設定を行った後は、これを解除します。
検索エンジンのクロールを禁止する
User-agent: *
Disallow:検索エンジンのクロールを許可する
User-agent: *
Allow:FTPソフトでアップロード
上記の作業が完了したら、すべてのファイルをFTPクライアントソフトを持ちいて上記のサブFTPアカウントでアクセスし、ローカルのフォルダ(パソコン側)のファイルを、サーバの指定されたフォルダにアップロードします。
ブラウザで確認
FTPでのアップロード後は、ブラウザにURLを入力して表示を確認
数日後にGoogleのサイト内検索機能の動作確認やアクセス統計が集計されているかを確認して、ウェブ公開のための作業は終了となります。
以上のように、サスティナブル・アーカイブ・ギャラリーあまのがわでは、なんらかの事情でウェブサーバを閉鎖しなければならない場合においても、他のサーバへの引越しはフォルダを丸ごとコピーするだけでできます(Googleサイト内検索や、アクセス統計などのタグなどは書き換える必要がある)。それもうまくいかない場合においても、マスターとなるメディアファイルや目録情報さえ残っていれば、そこから共有のためのウェブサイトを構築することも不可能ではない。
今後、さらに技術が発展し、より高度で複雑になる時代があったとしても、このデータをそのまま未来へ残すための工夫を常に怠らないことが肝心です。
マスターとなるデータセットと共有のための静的HTMLに加えて、実はマスターリングのところでも記述した「はじめにおよみください.txt」にも可能性を込めています。さりげなく記述しましたが、はじめにおよみください.txtにおいて記述するフォーマットが確定していく中で、ただのテキスト文章から、XML形式によるデジタルアーカイブそのものを記述することができる可能性を持っています。そしてさらに、デジタルアーカイブ記述言語 DAML: Digital Archive Markup Language の可能性さえももっています。